インスタンスを保持(Preserve Instances)せずに書き出されたFBXファイルをBlenderで読み込んでインスタンス(Meshデータブロックのリンク)を復元してみるテストです。
Meshの同一性の比較として、頂点数、エッジ数、フェース数とバウンディングボックスが一致しているかどうかを比べています。無理やりhashを取得して比較のほうが良いかもしれませんが。
以下、スクリプトのサンプルです。
続きを読む “Blender:同じ形状を探してリンク”インスタンスを保持(Preserve Instances)せずに書き出されたFBXファイルをBlenderで読み込んでインスタンス(Meshデータブロックのリンク)を復元してみるテストです。
Meshの同一性の比較として、頂点数、エッジ数、フェース数とバウンディングボックスが一致しているかどうかを比べています。無理やりhashを取得して比較のほうが良いかもしれませんが。
以下、スクリプトのサンプルです。
続きを読む “Blender:同じ形状を探してリンク”「スッキリわかる機械学習入門[sukkiri.jp]」って数式がほぼ出てこない本で機械学習(ML)のお勉強中。今まで何度か挫折しましたが、他の参考書と比べていきなり数式が出てこずPythonさえ分かればなんとなくMLの表面が理解できるので入門として良いです。3Dソフト使うのにいきなり幾何計算の話されたらCG作るのイヤになりますやん?そんな感じ。コムズカシイ事はもうちょっと後回しです。
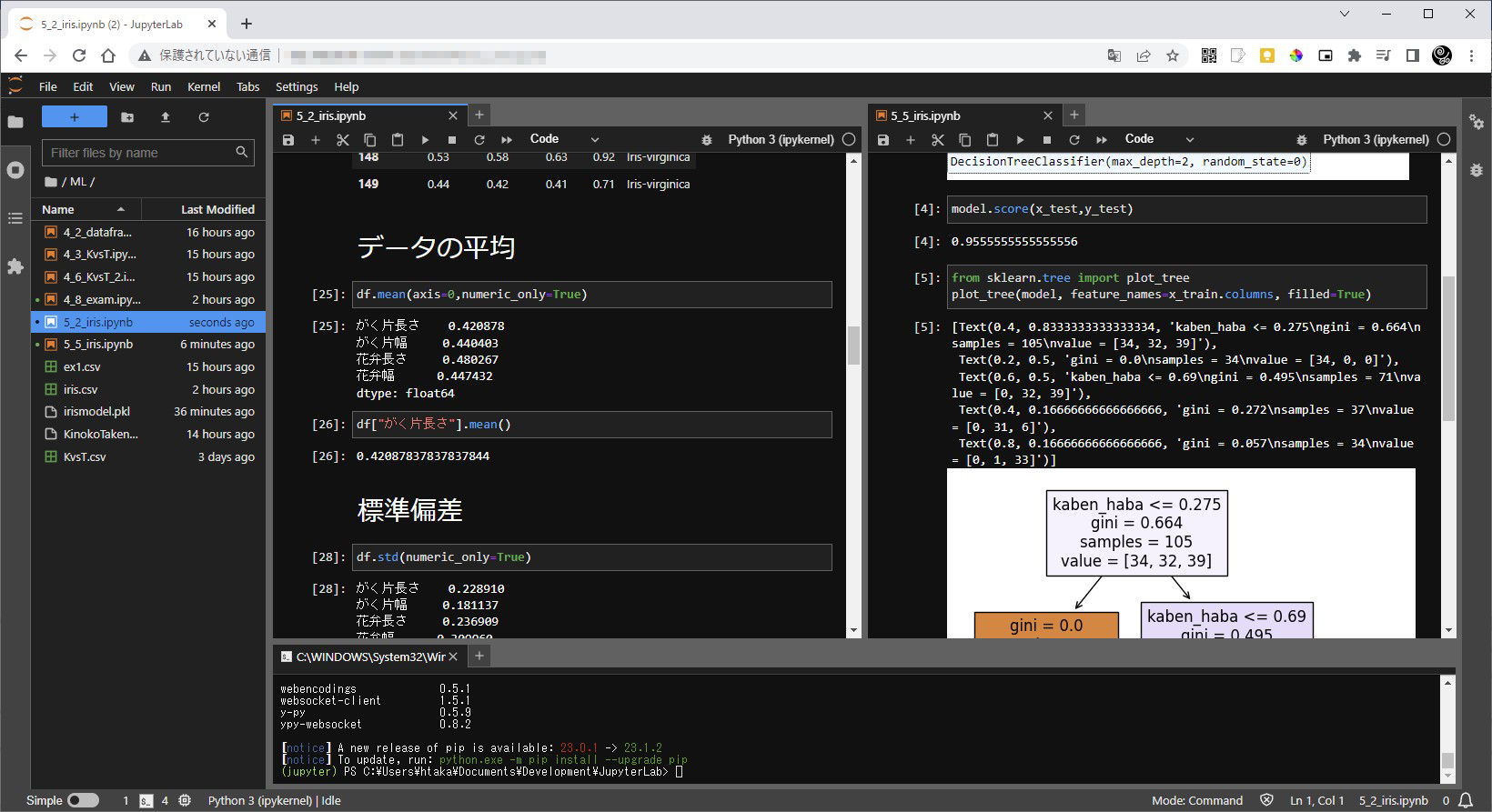
ところで、本書の153ページ/コード5-16でデータの平均を得る『df.mean()』がありますがエラーが出ます。
ValueError: could not convert string to float:
エラーを見る通り、文字列をFloat値へ変換できないというエラーです。NaNは既定で無視するのは良いとして文字列も数値に変換して計算しようするみたいですね。実際には以下のようにして数値のみ計算させます。標準偏差stdなども同じだと思います。
colmean = df.mean(numeric_only=True)
「第1版第5刷発行」の本ですが、正誤表にもない様です。Anacondaに付属のJupyterLabの使用を前提で書かれていますが、僕はjupyterlabパッケージとその他、scikit-lean、pandas、matplotlibをpipでインストールして使用しているので環境は少し違います。もしかしたらそのせいかも。
モデルに学習させるまでに、欠損データの補完や外れ値の削除、教師データと評価データの分割とデータの操作の手順が多いんですね。そこAIがやれよと思ってしまいます。
本が届いたときは600ページもある分厚さでビビりましが、6時間ほどで半分くらい進みました。
まだまだPandas.DataFrameの操作に慣れません。

MayaのShelfの整理です。よく使うスクリプトはメニュー化していますのでShelfには何かに使ったけどもはや何に使うのかよくわからんスクリプトがゴロゴロしてます。どんどん削除してもいいけどもしかしたら何かの参考になるかもって事でブログにバックアップです。
動くかどうかは保証しません!(The scripts below was written by me a long time ago. I can’t promise that it will work properly!)
機能の分からんモノがたくさんあるのでまた次の機会に載せるとして今日のところは3つ。まず1つ目はシーンからスムースメッシュがかかったメッシュオブジェクトを選択するもの。なんのために?
#Select smooth meshes import pymel.core as pm mesh_shapes = pm.ls(type='mesh') smooth_meshes = [] for s in mesh_shapes: pm.select(s) r = pm.displaySmoothness(query=True, polygonObject=True) if r != None and r[0] >= 3: smooth_meshes.append(s) pm.select(smooth_meshes)
2つ目、レガシーなレンダーレイヤーの削除かな?
続きを読む “Maya Shelfの整理”
夏前あたりからそろそろ調べ始めると思いたって既に年末。だってビルドとかメンドクサイし、Visual Studioをそのためだけにインストールしたくないし。
てことで、ビルド済みのパッケージがダウンロードできるところを探して見つけたのが以下2つ。(もっとあると思うけど)
NVIDIA版はMayaのプラグインがビルドされていないので、 今回試したのは2番目のほうです。NVIDIA版のほうがPython2一式と依存モジュールも含まれているので付属のツールusdview等を実行するだけならそっちのほうが簡単だと思います。
続きを読む “Pixar USDを試してみる”
Maya nParticleのキャッシュファイルを自前で作成したくなって、まずは読み込みから。
Devkitの中に「cacheFileExample.py」が入ってますが間違ってる箇所が多いので、必要のないものをバッサリ削って、整理して。で、いちから書きました。
One File/One file per object なmcxファイルの読み込みテストです。PythonスクリプトはTest for Reading mcx file[GitLab]へ置きました。
読み込み結果は長いので別ページ。
続きを読む “Reading mcx part1”